Improving configuration and monitoring of Nvidia GPU servers at CERN
One of Techlab’s main activities, arguably the most popular one, is the provisioning of GPU resources. In addition to user support, this process involves the complete configuration, administration, lifetime management and maintenance of the systems. Due to the high demand, turnover rate and variety of configurations according to user needs, the existence of an efficient and effective system to handle the configuration and monitoring of GPU resources is fundamental in order to minimize the time cost and to anticipate and investigate potential problems or performance concerns.
We introduce an improved framework for the management of GPU resources at CERN, improving on the current Techlab processes by moving from developing and maintaining in-house solutions to exploiting organization-standard tools and frameworks in a way more cohesive and integrated with CERN’s cloud configuration and monitoring infrastructure.
First we introduce a new module for Puppet for the deployment of CUDA libraries on Nvidia GPU systems. Then, we describe the software developed for the collection of GPU metrics and the necessary steps to set up a dashboard for these metrics, capitalizing on CERN’s monitoring infrastructure.
Improving the deployment of CUDA libraries with Puppet#
We can divide Techlab’s GPU offer into Nvidia and AMD GPUs. This document will only refer to the configuration of Nvidia GPUs. Within Techlab’s Nvidia GPU offer, we make the distinction between GPU servers and GPU Virtual Machines (VM). Beyond the obvious physical versus virtual differences, this distinction has implications in terms of power, access policy and lifetime management.
GPU servers’ GPU models are considerably more powerful than GPU VMs, and they are lent on a shared access policy, where users from different projects share the resources. In contrast, GPU VMs are provided on an exclusive access policy, where each VM is guaranteed to provide access to users associated to a single request or project. Furthermore, servers require configuration changes on the GPU side only for update or troubleshooting operations, while the lifetime management of a GPU VM takes a radically different approach, providing users with a new VM for each new request and destroying the VM at the end of the loan period.
The current GPU configuration implies a tedious manual process of installation and redistribution of software, requiring a new download of the binaries and its deployment on every node for each update of the software. This is specially costly taking into account the high turnover rate of GPU VMs and their particular lifetime management.
We rethink the configuration process by rewriting it into CERN’s automation framework, Puppet, first developed and tested extending Techlab’s hostgroup (node cluster) configuration files and then factored out into a Puppet module.
Puppet modules act as reusable and shareable building blocks for the Puppet configuration, each managing a specific task in the infrastructure. Factoring out our CUDA configuration code into a Puppet module allows for the reuse of the code by other teams of the organization, such as the cloud team and CMS’s Patatrack team.
The CUDA Puppet module has two responsabilities: installing the CUDA repository and installing the specified version of the CUDA libraries with the NVidia proprietary drivers. In addition, and because Nvidia broke its naming conventions for the CUDA libraries in version 10.1, several softlinks are created for applications that require by default the libraries to follow previous naming conventions, such as TensorFlow. The module’s code can be inspected on the following gitlab repository: https://gitlab.cern.ch/ai/it-puppet-module-cuda/tree/master/code
To load the puppet module within CERN’s Puppet managed infrastructure and apply the puppet configuration, the following lines should be added to the node or hostgroup manifest:
class {'::cuda':
version => $cuda_version,
install_libraries => $install,
}
where $install is a boolean flag signaling if the libraries will be installed in addition to the repository, defaulting to true, and $cuda_version is a real number specifying the CUDA version to install, from 9.0 onwards. In case of not specifying a version value, we default to the latest version available.
Monitoring GPU metrics with collectd and Grafana#
In order to better evaluate the usage, performance and potential issues related to the GPU devices, we deploy monitoring tools on Techlab nodes that extract metrics and indicators from the GPUs in a recurring way and generate their time series visualization for further inspection.
Techlab’s previous monitoring solution consisted of a daemonized python process gathering GPU metrics every 5 minutes and generating time series plots using matplotlib. This system, deployed to each gpu node with Puppet at configuration time, presented several disadvantages. Both data and graphics were stored locally, comsuming disk space over time and available to users with root access, a frequent case in GPU VMs. The monitoring code was deployed with the installation code, and was rather limited in terms of metrics displayed. Finally, opening separate graphics files for each metric was not the most convenient workflow, and was intended more for troubleshooting and post-mortem analyses than for continuous monitoring.
Instead, here we introduce a new, less complex and more streamlined approach to the GPU monitoring process, taking advantage of CERN’s monitoring infrastructure (Figure 1) to visualize several performance metrics and indicators from Techlab’s GPUs. Particularly, we exploit the workflow leveraging collectd for the extraction of metrics and grafana for its visualization. We first introduce the collectd plugin developed for GPU data collection and its possible configurations, and then we describe the process of visualizing these metrics in grafana, illustrating several dashboard examples.
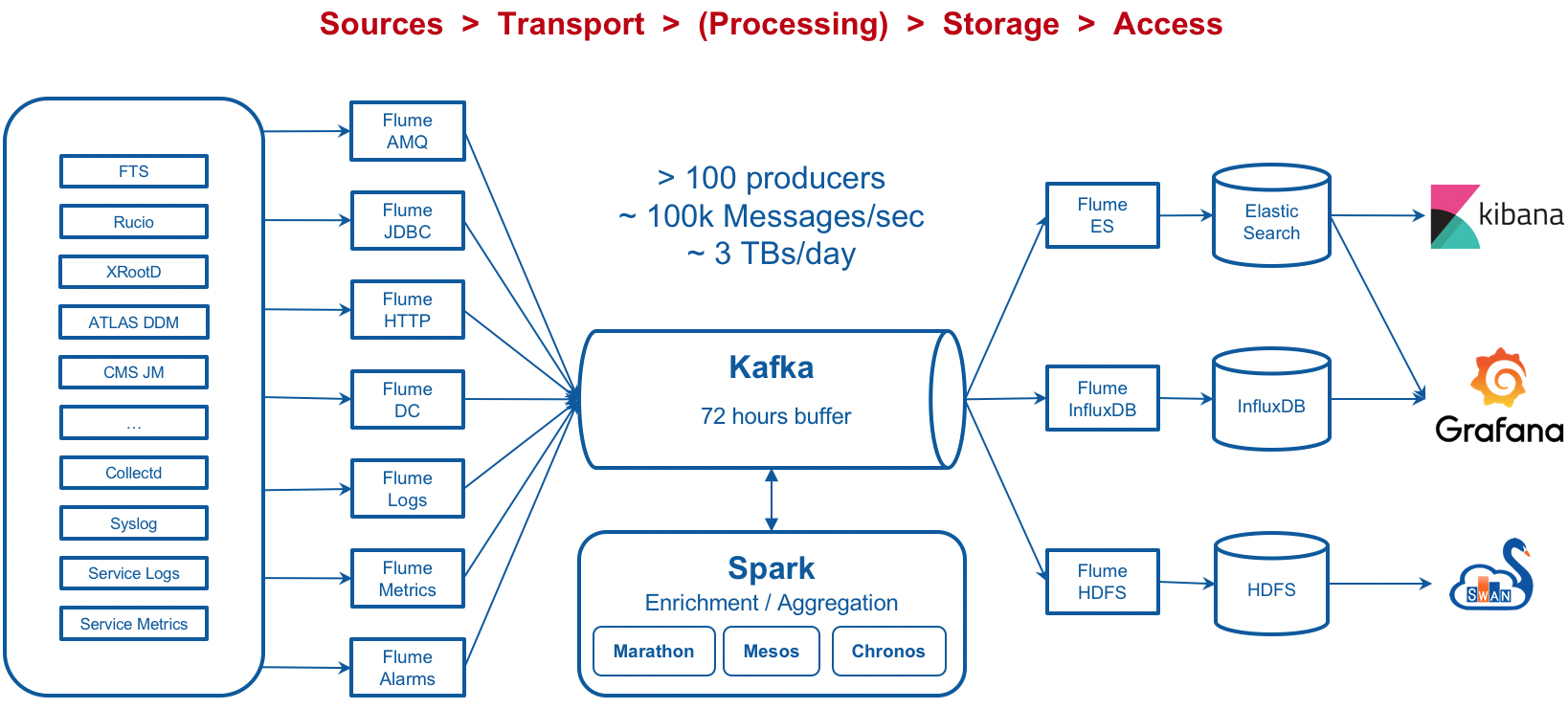
Figure 1: Monitoring service architecture at CERN. CERN IT Monitoring docs
A CUDA monitoring plugin for collectd#
Collectd is a Unix daemon that collects, transfers and stores performance data of computers and network equipment. At CERN, collectd is the standard tool used to extract metrics and alarms from the nodes and publish them into the data monitoring pipelines for future analysis and monitoring.
We contribute the collection of GPU performance and error metrics to CERN’s collectd and monitoing infrastructure, by developing a collectd plugin that exploits the Nvidia system monitoring interface (nvidia-smi) to extract these metrics from the GPUs. Several versions of collectd-cuda can be found online, including an official one. After a preliminary analysis they were deemed either not complete and configurable enough, or in a stalled development status. We took the decision to develop a new version, adapted to our needs, and then initiate discussions to contribute our developments to the official cuda-collectd plugin.
In addition to defining the collection interval, we can configure the plugin attending to three metrics collection blocks:
- Basic: set of performance metrics, such as temperature and percentage of usage, and baselines, such as enforced power limit and power limit, relevant for any workflow.
- Graphics: graphics collected metrics, relevant only in graphic operations.
- ECC errors: error correcting memory metrics, relevant to profile memory errors during execution.
where the basic collection block is always collected and the graphics and errors collection blocks are boolean flags that are not activated by default.
In systems with Security-Enhanced Linux (SELinux), the collectd processes execute within the very restrictive collectd_t Security-Enhanced Linux (SELinux) domain. Any access to a different domain or type from within the collectd SELinux context is denied if not explicitly allowed by a policy rule. For this reason, we implement and provide the set of SELinux policy rules to allow the collectd process access the resources required by the nvidia-smiexecution.
The code for the CUDA plugin and the associated SeLinux targeted policy package can be found on Techlab’s gitlab profile.
Monitoring GPU metrics on Grafana#
In construction…